LoRA作成のための素材準備[SDXL]
Preparation of materials to create LoRA.

オリジナルのLoRAを作るための事前準備編にゃ。
StableDiffusionの醍醐味というべき自分用のLoRAが作れるにゃ。
Roopでお気軽に似たような顔のキャラと作れると言っても学習したLoRAが使えた方が便利なのにゃ。
1枚ディープフェイク画像を作ろうと思ったらRoop。色んな構図でキャラと作りたいと思ったらやっぱりLoRAがいいのにゃ。

そうだにゃ。
それぞれ使い分けが出来ると便利なのにゃ
LoRAで利用する素材準備にはTaggerが必要なのにゃ。
導入がまだの人は入れるのにゃ。
Taggerの導入
画像に対してタグ(キャプションや説明文)を自動的に生成する機能を提供します。
How-To Guides
Step 1: 事前準備
SDXL&Pory用LoRAの作成の準備です。
SD1.5と比べて圧倒的に似せることが可能なためこちらを作り始めるとSD1.5は不要になります。
最大のポイントは1024x1024以上の画像縦横比は気にせずできるだけ高解像度の画像を集めます。
.png、 .jpg、 .jpeg、 .webp、.bmp をサポートします。 ただあまりにも大きいサイズは2048x2048以下に加工したほうが良さそうです。
作ろうとしているLoRA形が単純なものであれば最低20枚ほどでそれっぽく作れます。
リアルな人物を覚えさせるのであれば最低100枚はあった方が良いと思います。
画像に関しては多ければ多いほど精度がよくなるようです。
ただ、教師データは多ければ多いほど良いとされてますが実際は多くても1000枚以下が良さそうです。
用意できた教師画像が512x512などの場合でも大丈夫です。
Guide12:「Ultimate SD Upscale」を利用して高解像度で1024x1024以上の画像にアップスケールすればOKです。
抑えるべきポイントを纏めます。
・1024x1024以上のサイズであること
・作成する対象が鮮明であること(ボケたりしてるとそのまま学習されます)
LoRAを作成するためのフォルダ名はわかりやすく「C:\LoRA_make」にしておきます。
そのフォルダの下に「input_images」「output_images」を作成します。※いずれの名称も任意でOKです。
input_imagesには学習する教師画像を入れます。
このフォルダの中で作業を行っていきます。
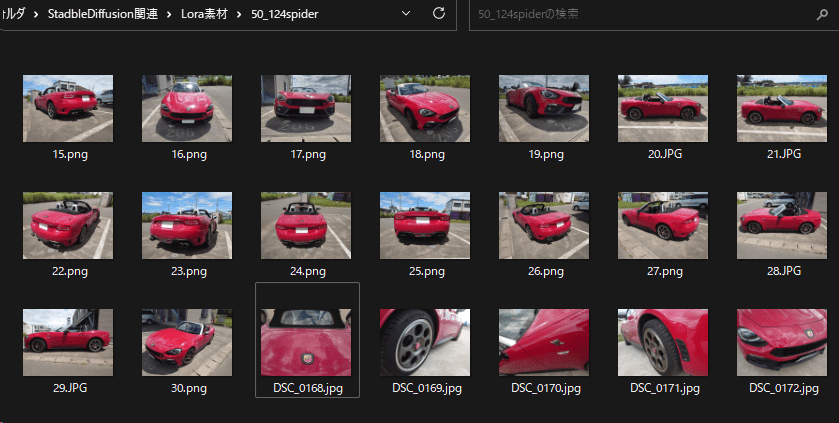
今回は形が固定である車のLoRAを作ります。
人物などは表情により変化したりポーズも変わったりするので試行回数を繰り返さないと行けないですが車の場合は静物なので比較的簡単に作れます。
比較的レアな車であるAbarth124spiderを学習させます。
CivitAiでは見かけないLoRAであり車のLoRAは数が少ないので取り上げました。
この美しい独特のフォルム車LoRAを作ることが出来るのでしょうか。

ここから先は次の補助ツールを使います。
Image Renamer and CSV Processor
このプログラムは以下の機能を提供します。
・ファイルのリネーム機能
・Taggerにより生成されたtxtの文字収集機能
・収集した文字の日本語訳付加機能
・選択項目の除外機能
以上の処理が出来るツールが他にあればそれを利用するでもOKです。
これ以降は上記のプログラムを利用することを前提に説明します。
ダウンロードしたLoraCSVprocessorXXX.zip(XXXの部分はバージョン数)を解凍してください。
LoraCSVprocessorXXX.exeを起動します。
次のアプリが起動します。
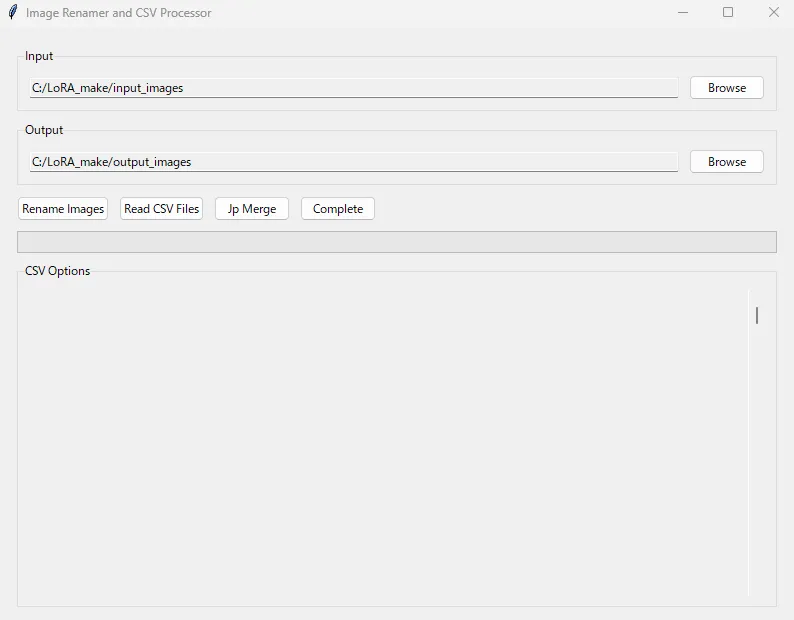
inputには先ほど作成したinput_imagesを指定します。
outputには先ほど作成したoutput_imagesを指定します。
input_imagesにはサンプルですが以下のような画像が入っています。
000~999までの名称のファイルが1つでも存在する場合は一度個別にRenameして下さい。
フォルダの画像を全選択してaaaという名称で名前の変更を行うとaaa.png、aaa(1).png、aaa(2).pngという感じで変更できます。

まずはLoRA用に画像のファイル名を揃えます。
アプリの「Rename Images」ボタンを押してください。
3桁の連番の名称に変換されます。
変換されたらTaggerを利用してcsvのタグを作成します。
Step 2: タグの生成
StableDiffusionのTaggerを使ってタグを作成します。
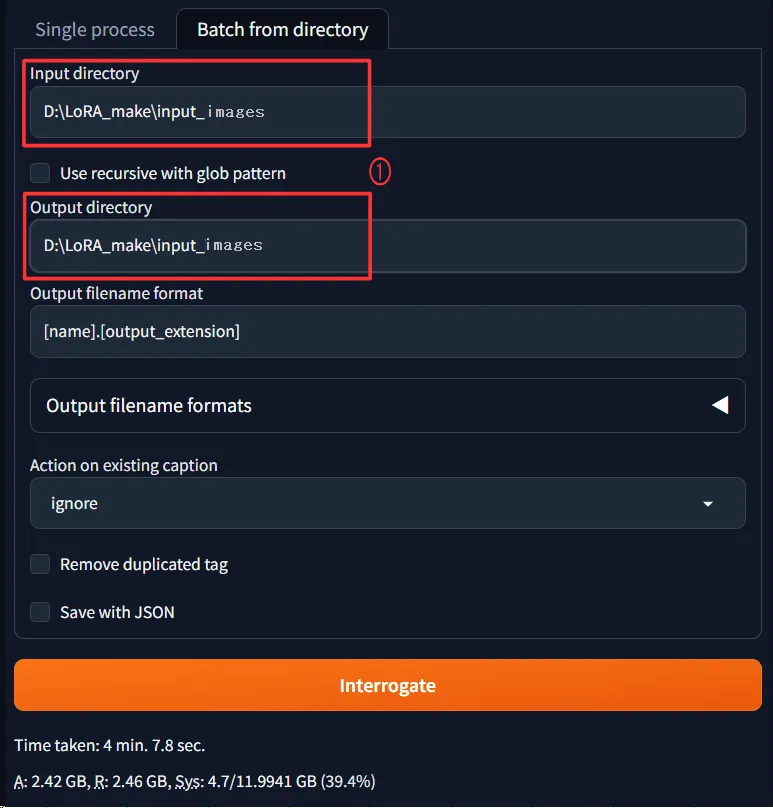
StableDiffusionを起動してTaggerタブをクリックして更にその中のBatch from directoryタブを開きます。
Input directoryとOutput directoryに先ほど作成したinput_imagesフォルダを指定します。
※両方とも同じ場所なのでOutput directoryは入れなくてもOKです。省略可能です。
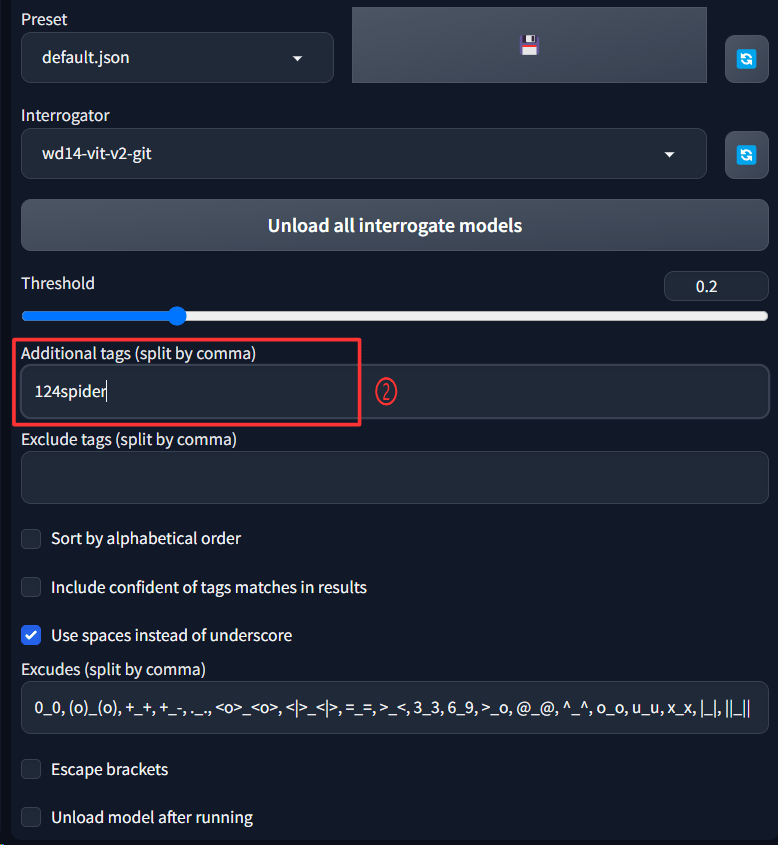
下の方にあるThresholdは0.2ぐらいにし、Additional tagsには今回のLoRAのトリガーとなるタグを指定します。
今回は124spiderにします。
「Threshold」設定は、Taggerが出力するPROMPTの影響度の閾値を指定するものです。
例えば、Thresholdを0.35に設定すると、Taggerは影響度が上位35%以上の単語をPROMPTとして出力します。
0.2という設定は20%以上の単語を出力することになるので0.35の設定よりも多くの単語を吐き出します。
ここまで設定できたらInterrogateをクリックします。
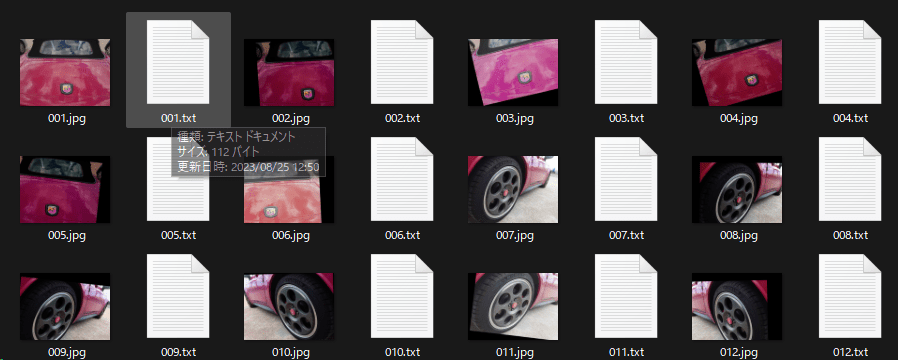
すると画像フォルダにtagが記載されたtxtファイルが画像の枚数分作成されます。
Step 3: タグの加工
タグが記載されたtxtが作成されたら一旦Stable Diffusionの出番は終了です。
アプリに戻ります。
アプリの「Read CSV Files」ボタンを押してください。
読み込みが完了するとCSV Optionsの部分にtxtファイルに記載されたすべてのタグが表示されます。
またoutput_imagesフォルダには「all_words_en.csv」と「all_words_jp.csv」ファイルが作成されます。
all_words_en.csvをメモ帳などのテキストエディタで開いて下さい。
アプリと同じタグが存在してます。

すべてのタグを選択して右クリックでコピーを選択します。
コピーしたタグを翻訳サイトで日本語に変換して下さい。
今回はDeepLを利用しました。
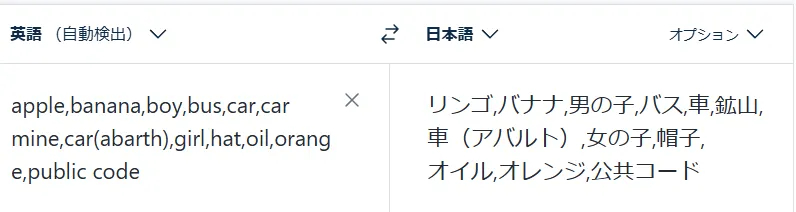
日本語訳されたタグをall_words_jp.csvに張り付けます。
先頭行は空だと正常に動作しないので空白が出来た場合は詰めて下さい。
タグが多いとたまに日本語訳の結果のカンマが読点「、」に変換される場合があるので読点は半角のカンマ「,」に置換して下さい。
張り付けた日本語訳を保存します。
英語のタグと一致させる必要があります。
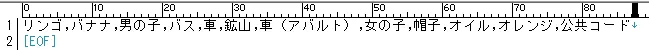
アプリに戻って「Jp Marge」ボタンをクリックします。
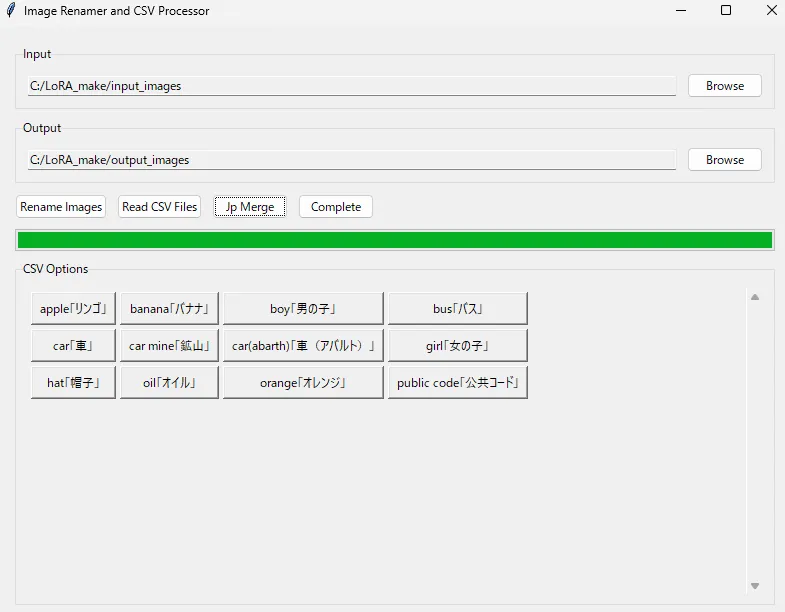
日本語訳が付与されたタグが表示されます。
ここからTaggerによって出来たtxtファイルのタグの選定に入ります。
ここが非常にポイントになるのですが、生成された画像のタグから学習してもらいたいものを「削除」します。
逆を書くと覚えさせたく無いタグを残します。
アプリのタグをクリックすると水色になりますが、この状態が削除するタグになります。
今回は表示されたタグの中で学習させたい車に関連するものを選択するので[car]と[car(abarth)]を選択した状態にします。
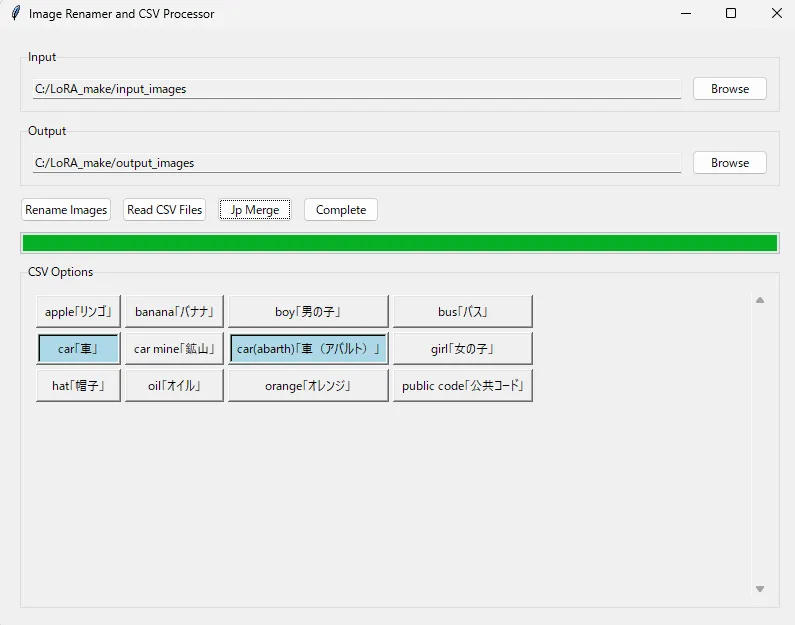
覚えさせたいタグの選択が完了したら「Complete」ボタンを押します。
すると、input_imagesに存在するすべての.txtファイルの中にあるタグから選択した[car]と[car(abarth)]が消えています。
この出来上がったtxtファイルと画像ファイルをLoRA作成用の画像フォルダに移動します。
Step 4: 教師画像の配置
Kohya_ssで教師画像を入れるフォルダを作ります。今回はimput_imagesフォルダの下に作成します。
このフォルダ名が重要になります。以下のルールで作成します。
数字_〇〇
この数字が画像1枚あたり何回学習するかを意味しており、〇〇に入る単語がLoRAを作るときのトリガーワードになります。
フォルダの数字ですが、学習の繰り返し回数になります。
後に出てくるStepの関係として以下の式が成り立ちます。
学習の繰り返し回数 × エポック数 = Step数
・学習の繰り返し回数(リピート数)とは、教師画像や正則画像を何回繰り返して学習するかを示す数字です。リピート数が高いほど、学習にかかる時間が長くなります。
・エポック数とは、教師画像や正則画像を一通り学習することを一回としたときに、何回学習するかを示す数字です。エポック数が高いほど、学習が収束しやすくなります。
リピート数とエポック数の関係性は正則画像を利用する場合は意味を持ちますが、正則画像を利用しない場合は10x20でも20x10でも同じです。
エポック数ごとにLoRAファイルを作成することが可能なので、個人的にはエポック数を10に固定して毎回10個のファイルを作成し、その中から良質なものを採用してます。
よって学習量を増やしたい場合はリピート数を増減させて調整します。
今回は以下のフォルダ名にしました。
20_124spider
先ほど作成したtxtファイルと画像ファイルを作成した20_124spiderに移動させます。
現時点のフォルダは次の状態になります。
C:\LoRA_make\input_images\20_124spider
これで準備完了です。
一番手間がかかる作業がこれで終わりです。あとはLoRAを作るだけです。
準備した素材を使って次の記事ではKohya_SSの使い方を解説します。

一度作業してみると次からはそんなに手間は掛からないにゃ。
一番大変なのは質の良い画像を集めることなのにゃ。
2回目からは全部読まなくても流れだけが解るように箇条書きで書いておくにゃ。
1.集めた画像をinput_imagesに配置する。
2.ツールを起動し「Rename Images」ボタンを押下する。
3.Taggerを利用してタグtxtを作成する。
4.「Read CSV Files」ボタンを押下する。
5.output_imagesフォルダに作成されるall_words_en.csvを翻訳しall_words_jp.csvに保存する。
6.「Jp Marge」ボタンを押下する。
7.CSV Optionsに表示されたタグから覚えさせるものをクリックする。
8.「Complete」ボタンを押下する。
9.リピート回数を設定したフォルダを作成し画像とテキストファイルを移動する。
次はいよいよLoRAの作成なのにゃ。
[PR]