Kohya's GUIを使ったLoRAの作り方
How to create LoRA using Kohya's GUI.

事前準備が終わってついにオリジナルLoRAの作成にゃ。
準備さえ出来ていればここでは設定を入れるだけで作成に進めるにゃ。
教師画像集めが大変だったにゃ。
早く出来上がりが見てみたいにゃ~

一度環境を作ってしまえば設定して作成するまで工程は簡単なのにゃ
LoRAを作成するにはKohya's GUIが必要なのにゃ。
導入がまだの人は入れるのにゃ。

Kohya's GUIの導入
LoRAという追加学習を簡単に行えるようにしたツールです。
How-To Guides
Step 1: Sorce Modelの設定
kohya_ssのフォルダにあるgui.batをクリックしてGUIを起動します。
起動直後はDreamBooth画面が開いていると思いますがそのとなりのLoRAタブをクリックして移動して下さい。
LoRAタブの初期画面がSorceModelタブになります。
この画面から設定して行きます。
以下の画像の項目が表示されてない場合はDreamBoothタブを開いてるかも知れませんので画像の一番上の部分でLoRAが選択されているか確認して下さい。
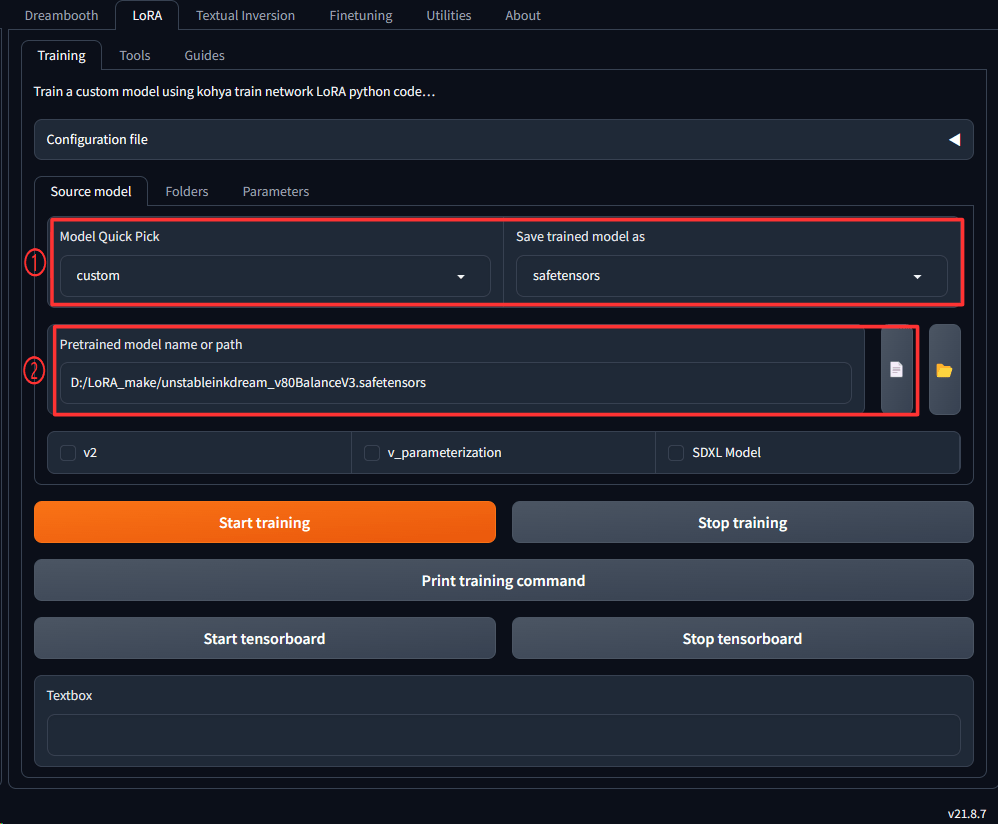
1.Model Quick Pickでcustomを選択します。Save trained model asの部分はsafetensorsを選択して下さい。
出来上がったLoRAの拡張子になります。
2.Pretrained model name or pathからベースとなるmodelを選択します。アニメ系などであればanyLoRAというモデルがあるのでCivitAIからダウンロードしてその辺を選んでみると良いかもしれません。
今回は安易ですがモデルの画像に車が使われていたのでunstableinkdreamという名前のLoRAをダウンロードしたのでこれを使います。
ここのタブ設定は以上です。全部の項目を説明すると長くなるので最低限LoRAを作るための設定のみして行きます。
Step 2: Foldersの設定
次に隣のタブのFoldersの設定を行います。
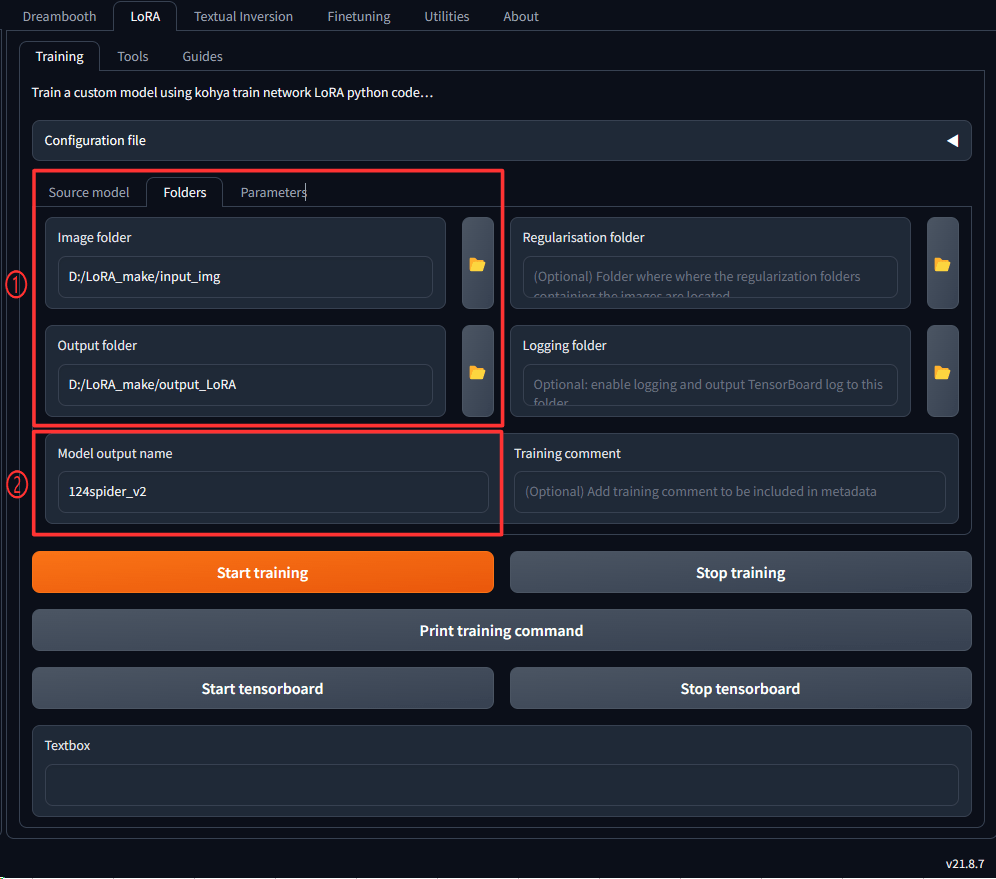
1.Image folderとOutput folderにそれぞれ該当のフォルダを設定します。
こちらは前回の準備編で作成したフォルダをそれぞれ指定します。
Image folderには教師画像が入っているフォルダを選択し、Output folderは出来上がったLoRAが入るフォルダーです。
2.Model output nameは出来上がるLoRAの名前です。ここにつけた名前で○○.safetensorsというLoRAファイルが出来上がります。
ここのタブ設定は以上です。
Step 3: Parametersの設定
次に更に隣のタブのParametersの設定を行います。
こちらは設定項目が沢山ありますが本記事では必要最低限に絞って設定して行きます。

Train batch size
まずはTrain batch sizeを設定します
モデルのパラメータを更新する際に一度に使用するデータの数を指定するオプションです。
バッチとは「いっぺんに読み込む画像の枚数」です。バッチサイズ2なら、一度に2枚の画像を同時に学習します。
train batch sizeを大きくすると、学習が速くなる可能性がありますが、グラフィックボードのメモリ(VRAM)の消費量も増えます。
逆に、train batch sizeを小さくすると、学習が遅くなる可能性がありますが、VRAMの消費量も減ります。
train batch sizeが大きすぎると、CUDA out of memoryというエラーが発生します。
エラーにならないギリギリでは学習速度が低下します。タスクマネージャーで使用メモリ量を確認しながら調整するとよいでしょう。
また、違う絵を複数同時に学習すると個々の絵に対するチューニング精度は落ちますが、複数の絵の特徴を包括的にとらえる学習になるので、最終的な仕上がりが良くなる可能性があります。
設定可能な最大値と1で出来を比べてみると良いかも知れません。
Epoch
次に設定するのはその隣にあるEpoch数です。
1Epochは1セットの学習を表します。1セットの学習とは教師画像数×リピート回数です。
ということは集めた教師画像数とフォルダ名称に設定したリピート回数を何回学習するかということになります。
LoRAの場合は3~10ぐらいで十分とのこと。
2023/10/10追記
教師画像が入っているフォルダに設定する数値(repeats)とepoc数(epochs)の関係性。
教師画像が少なくても十分な特徴を持っている場合は、repeatsを小さくしてepochsを大きくすることで、精度の高いモデルを作成できる可能性があります。
逆に、教師画像が多くても似たような特徴しか持っていない場合は、repeatsを大きくしてepochsを小さくすることで、多様な特徴を学習できる可能性があります。
Max train epoch
次のMax train epochはミニバッチ勾配降下法という学習手法を用いる際の設定値ですが、設定してみてよさそうなところを探るしかないということです。
そんなこと言い出したら答えなんて出ないので設定しないのもありです。
Save every N epochs
次のSave every N epochsは設定したepoch数ごとにLoRAを作成する設定です。
例えばEpochに10を設定してここに3の値を設定すると3,6,9,10のタイミングでLoRAファイルを作成します。
完成したLoRAが過学習になり使い物にならなかったら6回目で出来上がったLoRAを使うみたいな使い方が出来ます。
Caption Extension
次のCaption Extensionは元画像と一緒に入っているタグが記述されたファイルの拡張子を設定します。
このサイトの導入手順を行ったのであればtxtになります。

Mixed precision & Save presicion
次の行にすすんでMixed precisionとSave presicionですがこちらはGeforce40系の12G以上を使ってるのであればbf16でそれ以下であればap16を選択します。
その隣のNumber of CPU threads per coreはCPUのコアが同時に処理できる命令の数を表す指標です。
学習時のCPUコアごとのスレッドの数です。タスクマネージャーのパフォーマンスを見ながら増やすと良いです。

Learning rate
精度に関して重要な部分です。
学習の速度や精度に影響するパラメーターの一つで、大きすぎると学習が不安定になり、小さすぎると学習が遅くなります。
値が小さいほどゆっくりと学習を行い精度があがります。
値が大きいほどベースとなるモデルの影響を受けます。
デフォルトで1eー4(0.0001)になっています。
1e-4(0.0001)~1e-7(0.0000001)あたりから最適なところを探るとよさそうです。
1e-4の設定で作成後、他の設定値は同じまま1e-7を試してみた時にメモリ不足のエラーが発生したので値を小さくするほどメモリを消費する様です。
LR warmup
先の設定にあったEpochのどこのタイミングで学習率を最大にするかを設定します。
つまりEpochよりも大きな値を設定する意味がありません。
設定した値によって学習率が最大値に達するタイミングを制御します。
Epoch10でLR warmupを5にした場合は学習率の最大値に達する速度が早くそれ以降は一定に保たれます。
Epoch10でLR warmupを10た場合は最大値に達するまで徐々に学習率をあげ10で最大値に達します。
使い方としては1と10でLoRAを作成し理想的な方に近づけていきます。1の方が精度が良さそうであれば次は2と5で試してみるといった具合です。
Optimizer
Optimizerは選択するものによってかなり精度に違いが出ます。
Optimizerという部分でAdamW8bitが選択されてますが、これはVRAMの使用率が低くて精度が良いものということでデフォルトになってます。
しかし実感としては「AdamW」(32ビット)とか「Adafactor」がかなり精度が良いと思います。
「AdamW」(32ビット)はその名の通りデフォルトで選択されているものの32ビット版なので単純に考えると数倍結果が良いかもしれません。
「Adafactor」はAdam手法を取り入れつつ学習の進み具合に応じて学習率を適切に調節するのでLearning rate設定が自動で行われます。
この2点はより良い結果が得られるかもということを覚えておくと良いかもしれません。
ただしどちらもAdamW8bitよりVRAMを消費します。
「Adafactor」を使う場合はOptimizerの左にあるLR warmup(% of setps)の値を0にする必要があります。
0にしないと実行時にエラーになります。これに気づかずAdafactorを使えるようになるまでだいぶ悩みました。
また、他のOptimizer設定よりもLearning rateは高めの方が良いようです。0.001の高めの学習率が良いとされてます。
Adafactorは、AdamやRMSPropなどの他のオプティマイザーと比べて、学習率の初期値や減衰率に敏感ではありません。
そのため、あまり細かく調整する必要がなく、0.001という一般的な値で十分な場合が多いです
Adafactorは、学習率の減衰を指数関数的に行います。これは、学習が進むにつれて、学習率を徐々に小さくしていくことで、収束に近づけるためです。そのため、
初期値が少し大きめでも、最終的には小さな値になります。
とは言っても結局のところ正解は無いのでもう少し小さい学習率の方が良いかもしれませんし試すしかありません。
更にスクロールすると画像のMax resolutionとEnable bucketsの部分が出てきますが、ややこしい関係性なので理解しておいた方が良いでしょう。
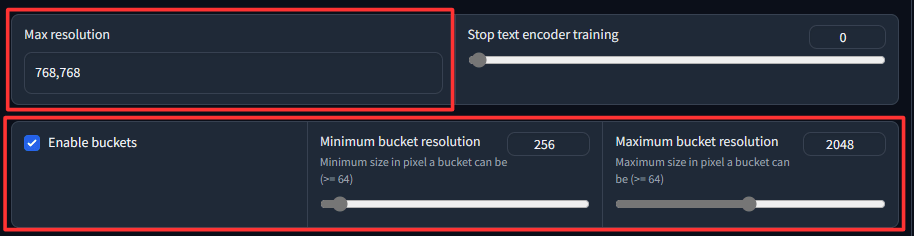
enable buckets & max resolution
enable bucketsとは、画像のサイズやアスペクト比に関係なく、追加学習を行うことができるようにするオプションです。
enable bucketsにチェックした場合、画像はバケットサイズという範囲に自動的にスケーリングされます。バケットサイズはデフォルトでは256-1024ピクセルですが、max resolutionで指定した値があれば、それが優先されます。
max resolutionとは、画像のサイズを制限するためのオプションです。
max resolutionで指定した値よりも大きい画像は、その値に合わせて縮小されます。
max resolutionで指定した値よりも小さい画像は、そのままのサイズで学習されます。
enable bucketsとmax resolutionの関係性は以下の通りです。
・enable bucketsにチェックしない場合: max resolutionの設定は必須です。max resolutionで指定した値よりも大きい画像は縮小され、小さい画像は拡大されます。画像のアスペクト比は無視されます。
・enable bucketsにチェックした場合: max resolutionの設定は必要ありません。画像はバケットサイズという範囲に自動的にスケーリングされます。画像のアスペクト比は保持されます。ただし、もし画像のサイズを制限したい場合は、max resolutionで指定することができます。

Network Rank & Network alpha
Network Rank(Dimension)の設定です。他のサイトでDimと書かれていたらこれのことです。
この値が大きいほど教師データに忠実になります。実感ですが上げれるだけ上げれば結果が良い気がします。
デフォルト8ですが4070TIのVRAM12Gでは620まで挙げてもエラーにならずかなり良い結果が得られてます。
Network alphaはデフォルト1になってます。情報元を忘れましたがNetwork Rankの半分の設定が良いと聞いたことがあります。
ただし関係性としてはNetwork Rank>=Network alphaになるようにすれば良いようです。
Network AlphaとNetwork Rankが同じ値の場合、効果は打ち消されます。
ベースとなるモデルとの関係性もあると思いますが、alphaを半分の値にするとガビります。1だとほとんど教育の効果が無い感じでした。つまり1~Network Rankの半分の間で良いところを探ることになります。
Advanced設定:
最後にアニメ系のLoRAの場合はAdvancedタブにあるClick Skipを2すると良いという情報があります。
これも本当に良いかどうかは試してみるしかないですが、今回は実写の車なので1のままにします。
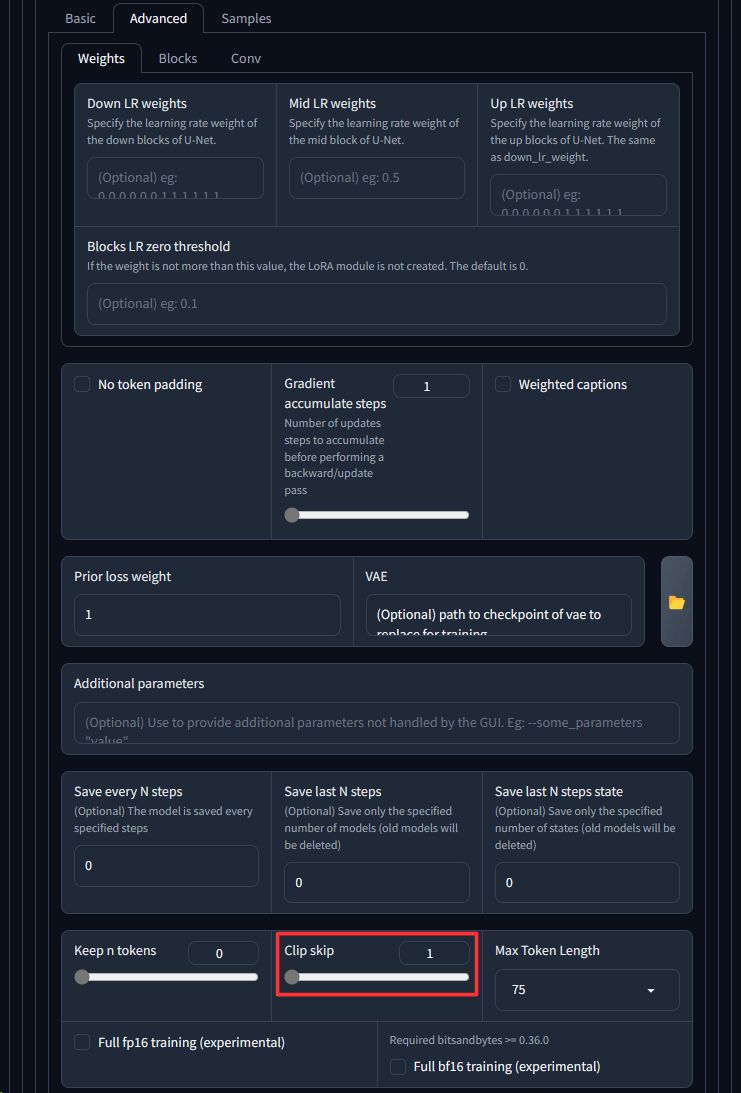
★Advancedタブ情報追加(2023/10/11)★

Gradient checkpointing
メモリ不足でエラーが出る場合はこのオプションをチェックするとかなり余裕ができます。
デメリットは速度低下ですが、そもそもメモリ不足でエラーになるわけですから、その場合には必須です。
Gradient checkpointingとは、深層ニューラルネットワークを学習する際にメモリ使用量を削減するための手法です。通常、バックプロパゲーションで勾配を計算するためには、フォワードパスの出力を全て保存しておく必要がありますが、これはメモリを多く消費します。Gradient checkpointingでは、一部の層の出力だけを保存しておき、他は破棄します。バックプロパゲーションでは、保存した層から再度フォワードパスを計算して必要な出力を得ます。これにより、メモリ使用量をO (sqrt (n))まで減らすことができます。ただし、計算時間は増加します。
memory efficient attention
こちらの設定もLoRAの作成時に使用するメモリ量を削減することができます。
具体的には、attentionという機構を使って、画像の特徴を関連付ける際に、一部の計算を省略することでメモリ効率を高めます。
ただし、このチェックボックスをオンにすると、LoRAの品質が若干低下する可能性があります。
Full bf16 training(experimental)
RTX3XXX以上のグラボの場合はこのチェックをすることで速度向上とメモリ消費を抑えれる可能性があります。
ただしモデルによっては上手く動かない可能性があるので、有効にした場合と無効にした場合を比べてみて効果があれば有効にするのが良いです。
現時点では実験的な機能らしく試した結果、速度が見込めない場合は無効で使うと良いかもしれません。
ベースとなるモデルに依存するようなのでモデルごとに効果が出るか試す必要があります。
Persistent data loader
このチェックボックスは、学習データをメモリに保持するかどうかを選択するオプションです。
学習データをメモリに保持すると、学習速度が向上しますが、メモリ使用量が増加します。
学習データをメモリに保持しないと、学習速度が低下しますが、メモリ使用量が減少します。
VRAMに余裕がある場合はチェックすると生成速度が高まります。
Color augmentation
LoRA学習時にメモリ効率の高いAttentionレイヤーを使用するかどうかを選択するオプションです。
メモリ効率の高いAttentionレイヤーとは、xformersというライブラリに含まれる、メモリ使用量を削減しながら高速なAttention計算を実現するレイヤーのことです。
メモリ効率の高いAttentionレイヤーを使用すると、以下のようなメリットがあります。
・メモリ使用量が減少するため、GPUメモリが少ない環境でもLoRA学習が可能になる。
・Attention計算が高速化されるため、学習時間が短縮される。
しかし、メモリ効率の高いAttentionレイヤーを使用すると、以下のようなデメリットもあります。
・LoRA生成の品質が低下する可能性がある。
・xformersのバージョンによってはエラーが発生する可能性がある。
VRAMにかかわるので取り上げましたが、品質が下がる可能性を含むのでVRAMが足りないなどでなければ基本チェック無しで良さそうです。
Noise offset type
載せるべきか迷った部分ですが参考までに記載します。
このオプションは、LoRA学習時に教師データの画像に追加するノイズの種類を指定するものです。
ノイズとは、画像にランダムに発生する小さな変化やぼやけなどのことで、画像の品質を低下させる要因となります。
しかし、機械学習においては、ノイズを適度に加えることで、学習の効果を高めることができる場合があります。
なぜなら、ノイズを加えることで、教師データの多様性や表現力が向上し、モデルが教師データに適応しすぎることを防ぐことができるからです。
Originalが選択されていればノイズを使わないということになりますが、学習結果にちょっとしたスパイスを加えたい的な要素のようです。
解説だけ読んでると通常はそのままがよさそうです。おまじない的に適用したら良いものになるかも的に使う場面があるかもといった所。
Don’t upscale bucket resolution
LoRA学習時にメモリ効率の高いAttentionレイヤーを使用する場合に、Attention計算の解像度を上げるかどうかを選択するオプションです。
解像度を上げると、以下のようなメリットがあります。
Attention計算の精度が向上するため、LoRA生成の品質が向上する可能性があります。
Attention計算の安定性が向上するため、学習の収束が早くなる可能性があります。
しかし、解像度を上げると、以下のようなデメリットもあります。
メモリ使用量が増加するため、GPUメモリが少ない環境ではLoRA学習ができなくなる可能性があります。
Attention計算が遅くなるため、学習時間が長くなる可能性があります。
Parameterに関する設定はここまでです。
Step 4: LoRA作成の実行
ここまで設定が出来たらいよいよ実行です。
「Start traning」を押してLoRAを作成しましょう!
長かったですが、一度覚えてしまったらほぼ固定値なので次からは楽です。
実行ボタンを押すと以下のような感じでStepが進んで行き100%になったらLoRAの完成です。
場合によっては数時間かかるので寝る前とかにポチっと実行して置くのがお勧めです。
寝る前に以下のプログレスバーの0%が表示されるまでは見届けましょう。
もしもメモリ不足などでエラーが出る場合はこの表示が行われる前にエラーになります。
逆にここまで表示が行われたら時間がかかれども後は待つだけです。

実際のPCはどんな感じかと言いますと自分の環境だとGPUは12GのVRAMはフルで活用され、PCに乗ってる128Gのメモリは半分程の60Gほど消費します。
さて、実際出来上がったLoRAを試した結果ですが、比重0.8でこんな感じの絵が出来ました。

実感メモ
1カ月ほどLoRAを作り続けた実感まとめ。
キャラ画風に関するLoRAを作り続けました。その実感メモ。
教師画像 150枚、300枚 ・・・教師画像は多い方が良いという話がありますが300枚にしたらガビりました。画風を覚えさせるには厳選して100枚前後がよさそうです。
実際に出来上がった絵を比べてみても倍の方が似てるかといえばそうでもありません。
ただし20枚などの明らかに少ない枚数の場合は似せることが出来ないと思います。
repeat数 20 ・・・まったく似ない。
repeat数 30 ・・・少し似てるか。
repeat数 40 ・・・だいぶ似てくる。
repeat数 50 ・・・丁度よさげ。この辺の前後で調整した。
repeat数 60 ・・・似てるけど絵が濃くなる。
repeat数 70 ・・・似てるけど絵がギトギト感が出てくる。
正則化画像を使わない場合は教師画像×repeat数が5000~10000の値で探ると良さそう。
この辺は教師画像の枚数とrepeatの乗算のStep数であたりをつけると良さそうです。
例えば150枚×50(repeat)=7500ですが、画像100枚の場合は75(repeat)にするなど。
Max resolution
512, 512 ・・・うっすら特徴を捉える。
768, 768 ・・・まぁまぁ特徴を捉える。
1024,1024 ・・・似とるやんけ。
batch 1, 2, 3, 8・・・速度に影響するだけで絵柄に影響を感じられない。
epoch数 1, 2, 6 ・・・途中のステップ数でファイルを作成するのに調整するイメージ。1~2で試して過学習じゃなかったら上げるのがよさそう。
学習率 0e-4~0e-7・・・値が小さいほど似る傾向にある気がするがAdafactorを使い始めてからは0e-4固定。
NetworkRank 128, 256, 512・・・大きいほど特徴を捉える印象。
NetworkAlpha Rankの半分またはそれ以下・・・半分だとガビりやすい気がする。かといって1に設定してる人を見たので試したところ全く似なくなりました。以降なんとなく8の乗算で調整してましたが設定値が少数まで設定できるということは関係無いだろうと思い、出来上がった時の絵を見ながら線が不安定なら下げてみてそうじゃないギリギリまで上げてみるようにしてます。
Alphaの探り方ですがRankの半分だと過学習になるのは解ってきたのでRankが512の場合、Alpha200と50ぐらいで作成してみて50の方がよさそうであれば80ぐらいで作ってみてと範囲を狭めて値を探る感じ。
まとめると、
・repeat数は少ないとベースモデルに沿った絵になり50前後まで上げないと特徴を捉えない印象。
・Max resolutionは特徴を捉えさせるなら1024x1024一択な気がする。
・epochは途中でファイルを生成するための調整に利用。
・学習率はAdamWを使っていた時は設定値が小さいほど良い気がしましたがAdafactorはあまり変化は無さそう。
2023/10時点ではこんな感じ。次の題材のLoRAを作ってみて学習結果が似るか実験してみる。
今回作ったものは150(教師画像) x 45(repeat) x 1(batch) x 1(epoch) 学習率0e-4 NetworkRank 512, NetworkAlpha 50, Max resolution1024x1024が良かったです。
RTX4070TIだとMax resolution1024x1024にするとbatch数は1じゃないとメモリが足りなくてエラーになるので1固定です。
長い解説だったのにゃ。
奥が深すぎて沼なのにゃ。
この作業も毎回全部読むのは大変だから箇条書きで書いておくにゃ。
1.gui.batでKohya's GUIを起動
2.LoRAタブに移動
3.SourceModelタブでベースとなるモデルの選択
4.Foldersタブに移動し教師画像フォルダとLoRAの出力先などを設定
6.Parametersタブに移動し、細かいパラメータの設定
7.Start traningで実行
なんども作業してるとふと忘れたときでもここを見るだけで作業できるにゃ。
ベースとなるモデルによっても調整が必要だからたまには詳細部分から読んでみるのが良いにゃ。
[PR]