LoRA作成のための素材準備
Preparation of materials to create LoRA.

オリジナルのLoRAを作るための事前準備編にゃ。
StableDiffusionの醍醐味というべき自分用のLoRAが作れるにゃ。
Roopでお気軽に似たような顔のキャラと作れると言っても学習したLoRAが使えた方が便利なのにゃ。
1枚ディープフェイク画像を作ろうと思ったらRoop。色んな構図でキャラと作りたいと思ったらやっぱりLoRAがいいのにゃ。

そうだにゃ。
それぞれ使い分けが出来ると便利なのにゃ
LoRAで利用する素材準備にはTaggerが必要なのにゃ。
導入がまだの人は入れるのにゃ。
Taggerの導入
画像に対してタグ(キャプションや説明文)を自動的に生成する機能を提供します。
How-To Guides
Step 1: 事前準備
画像縦横比は気にせずできるだけ高解像度の画像を集めます。
.png、 .jpg、 .jpeg、 .webp、.bmp をサポートします。
ただあまりにも大きいサイズは2048x2048以下に加工したほうが良さそうです。
作ろうとしているLoRA形が単純なものであれば最低20枚ほどでそれっぽく作れます。
リアルな人物を覚えさせるのであれば最低100枚は必要で、それでもなんとなく似てるかもなそっくりさんレベルというのが実感です。
色んな角度からの画像を用意します。
画像に関しては多ければ多いほど精度がよくなるようです。
教師データは多ければ多いほど良いとされてますが実際は多くても1000枚以下が良さそうです。
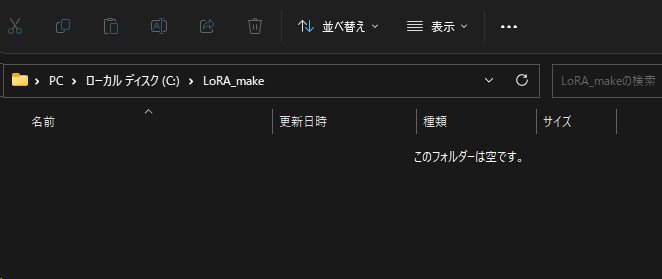
LoRAを作成するためのフォルダ名はわかりやすく「C:\LoRA_make」にしておきます。
このフォルダの中で作業を行っていきます。
今回は形が固定である車のLoRAを作ります。
人物などは表情により変化したりポーズも変わったりするので試行回数を繰り返さないと行けないですが車の場合は形が決まってしまっているので比較的簡単に作れます。
まず初めに集めた画像が数百枚あればベストですがその段階でなかなか大変な作業になってしまうので集めた画像を水増しして作業を行っていきます。
とても手作業ではやってられないのでプログラム的に対処することをお勧めします。
次のプログラムは個人的に作成した簡易的なPythonプログラムなので利用する人は自己責任で使ってください。
Python code
このプログラムは以下の機能を提供します。
・画像の水増し機能
・ファイルのリネーム機能
・Taggerによる生成txtの文字収集機能
・Taggerによる生成txtの特定文字除外機能
以上の処理が出来るツールが他にあればそれを利用するでもOKです。
これ以降は上記のプログラムを利用することを前提に説明します。
LoRA_makeフォルダの中でMake_LoRA.zipを解凍してください。
以下のフォルダができると思いますのでそれぞれ説明します。
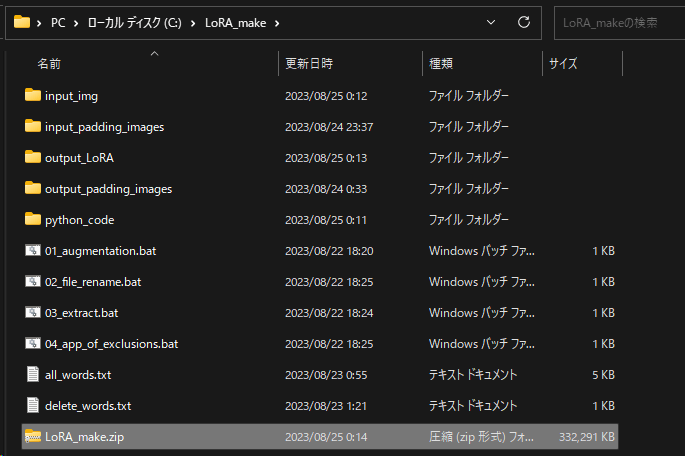
最初に各環境に合わせた設定を行います。python_codeフォルダの下にあるプログラムの設定を環境ごとに変更します。
全部で4つのファイルがありますがそれぞれのファイルをメモ帳などで開くと先頭の方にフォルダパスの設定が書かれてますのでご自身の環境に合わせてパスを変更してください。
例えば以下のような記述部分がDドライブを利用してる場合はD:に変更するなどです。
input_path = "C:\\LoRA_make\\input_padding_images\\"
CドライブにLoRA_makeを作成した人はそのままでOKです。
設定が終わったらimgaugの導入がされてない場合は次のpipコマンドでimgaugをインストールしてください。
コマンドプロンプトpip install imgaug --no-cache-dir
Windowsの検索ボックスにcmdを入力してコマンドプロンプトを起動したら上記のpipコマンドを入力すればインストールできます。
Pythonプログラムを利用する事前の設定は以上です。
今回は比較的レアな車であるAbarth124spiderを学習させます。
見たことがないLoRAであり車のLoRAは数が少ないので取り上げました。
この美しい独特のフォルム車LoRAを作ることが出来るのでしょうか。

Step 2: 画像の水増し
1000枚画像を集めた人はそれ以上は過学習になるかもしれませんので水増しする必要は無いのでこのステップは飛ばしてOKです。
さすがにそこまで画像は集められないと思いますのでそれ以外の場合はLoRAの精度を上げるために画像を水増しします。
input_padding_imagesに集めた画像を入れます。
画像を入れたら01_augmentation.batを起動します。
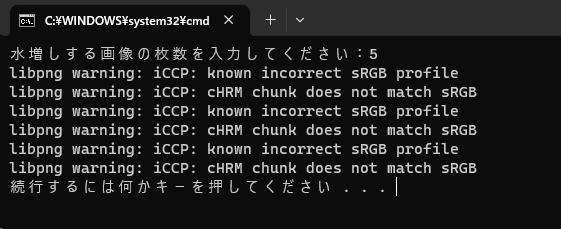
水増しする画像の枚数を指定します。
元画像を20枚集めたら10を入力すると1枚につき10枚の画像を水増しするので200枚の画像が作られます。
画像のようなwarningは無害なので気にしなくてよいです。
出ないようにする方法もありますが意味がないので割愛します。
処理が終わるとoutput_padding_imagesに水増しされた画像が生成されます。
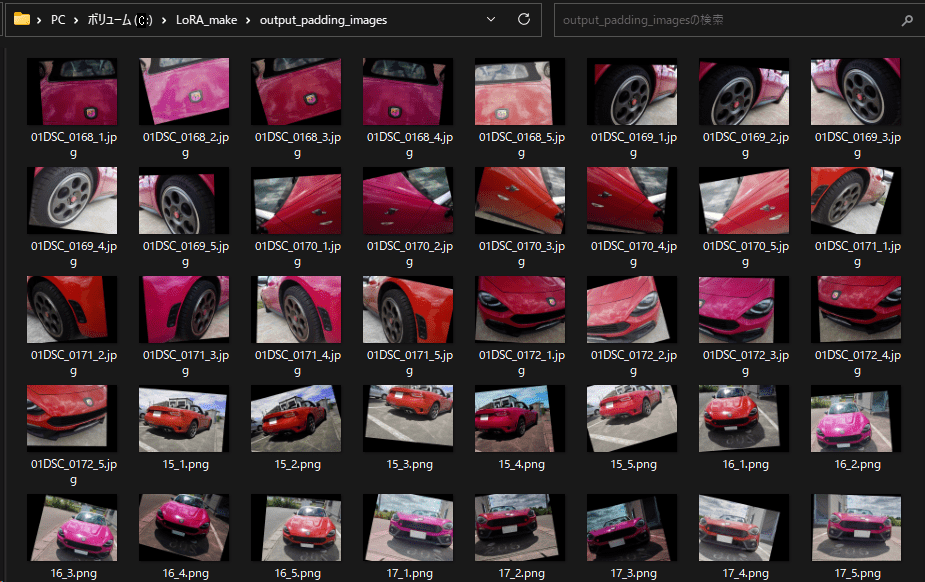
Step 3: LoRA作成のためのフォルダ作成
input_imgを開いてLoRAを作成するためのフォルダを作ります。
このフォルダ名が重要になります。以下のルールで作成します。
数字_〇〇
この数字が画像1枚あたり何回学習するかを意味しており、〇〇に入る単語がLoRAを作るときのトリガーワードになります。
フォルダの数字ですが、学習の繰り返し回数になります。
後に出てくるStepの関係として以下の式が成り立ちます。
学習の繰り返し回数 × エポック数 = Step数
・学習の繰り返し回数(リピート数)とは、教師画像や正則画像を何回繰り返して学習するかを示す数字です。リピート数が高いほど、学習にかかる時間が長くなります。
・エポック数とは、教師画像や正則画像を一通り学習することを一回としたときに、何回学習するかを示す数字です。エポック数が高いほど、学習が収束しやすくなります。
この辺調べたところその関係性が10x20と20x10でStep数が同じであれば結果が一緒ということでは無いらしく変に説明するとややこしくなるので結果だけ書くと、どっちが良いということは無いので実際に試してみてよい方を選んでねということみたいです。
今回は以下のフォルダ名にしました。
10_124spider
先述で水増ししたinput_padding_imagesとoutput_padding_imagesの画像を10_124spiderフォルダへ移動させます。
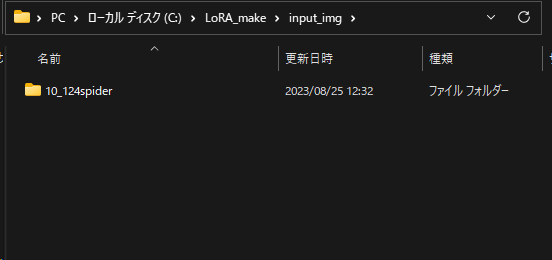
Step 4: 画像のリネーム
移動させた画像は連番のファイル名にする必要があります。
02_file_rename.batを起動してください。
フォルダ名を聞かれるので先ほど作成したフォルダ名の10_124spiderと入力してEnterを押します。
すると10_124spiderにあるファイルが連番のファイル名に変わります。
※すでに同じ名前の~というようなエラーが出る場合はすべての画像を選択して右クリックで名前の変更を押し適当にaaaなどに変更してEnterを押すとaaa(1)のような連番に変わるのでその状態になってからもう一度batを実行して下さい。
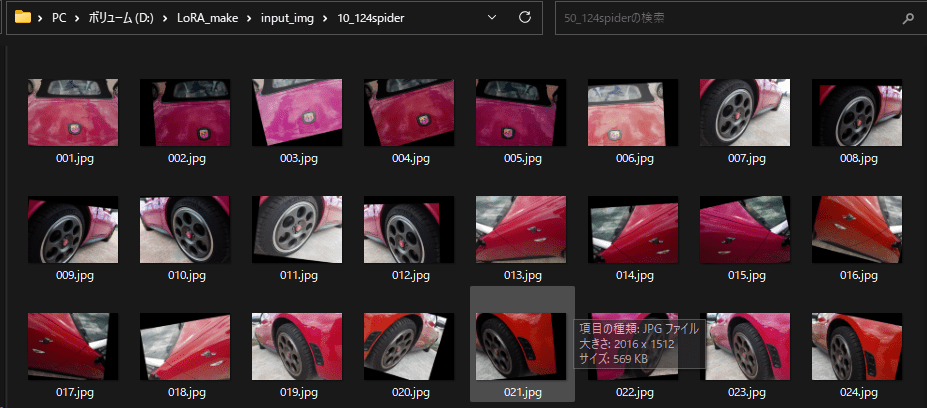
Step 5: タグの生成
StableDiffusionのTaggerを使ってタグを作成します。
Taggerタブをクリックして更にその中のBatch from directoryタブを開きます。
Input directoryとOutput directoryに先ほど作成したinput_img/10_124spiderフォルダを指定します。
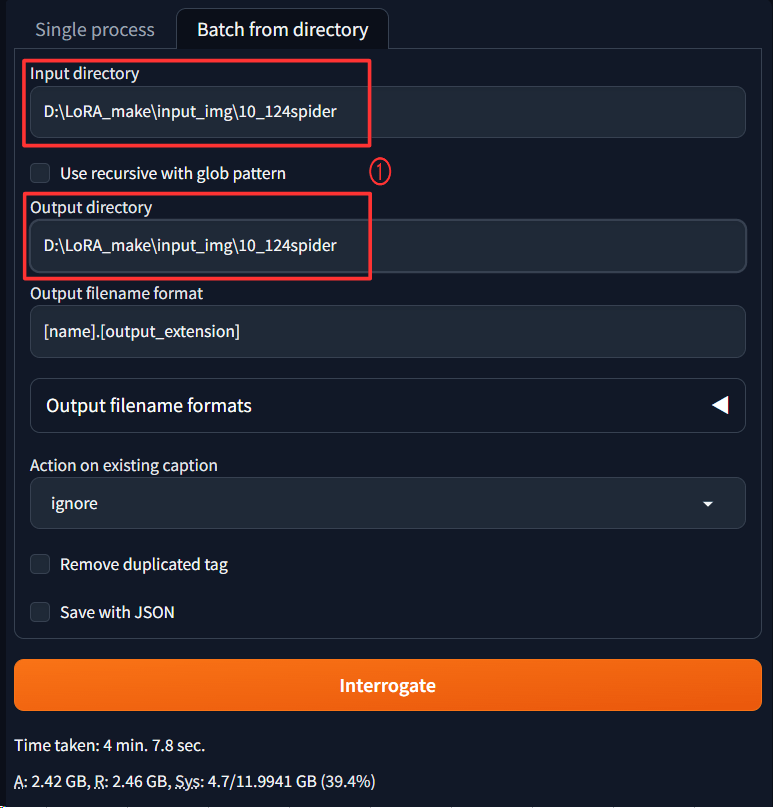
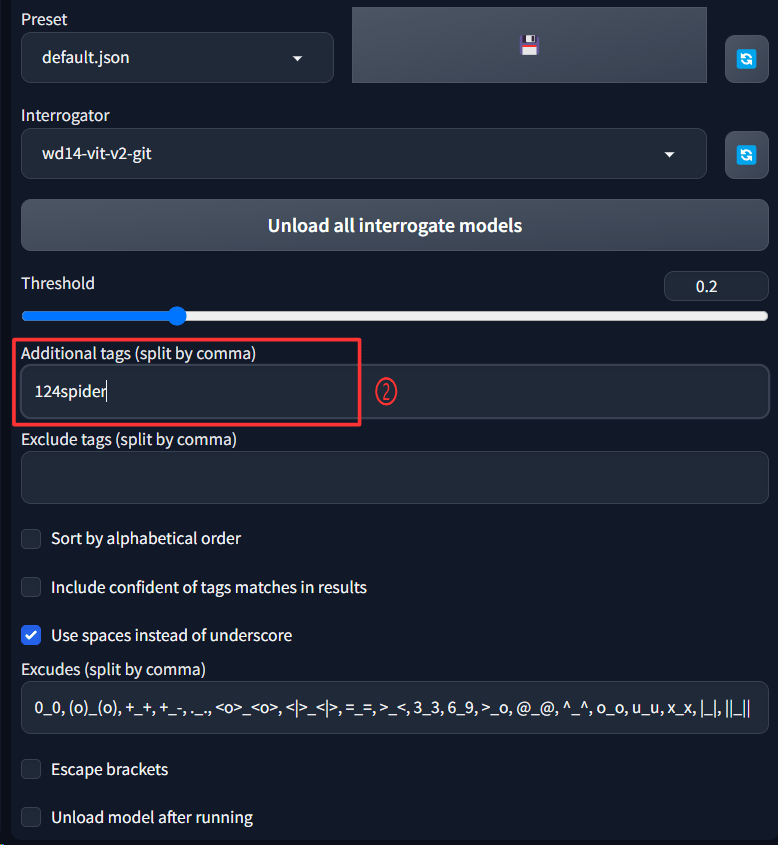
下の方にあるThresholdは0.2ぐらいにし、Additional tagsには今回のLoRAのトリガーとなるタグを指定します。
今回は124spiderにします。
「Threshold」設定は、Taggerが出力するPROMPTの影響度の閾値を指定するものです。
例えば、Thresholdを0.35に設定すると、Taggerは影響度が上位35%以上の単語をPROMPTとして出力します。
0.2という設定は20%以上の単語を出力することになるので0.35の設定よりも多くの単語を吐き出します。
ここまで設定できたらInterrogateをクリックします。
すると画像フォルダにtagが記載されたtxtファイルが画像の枚数分作成されます。
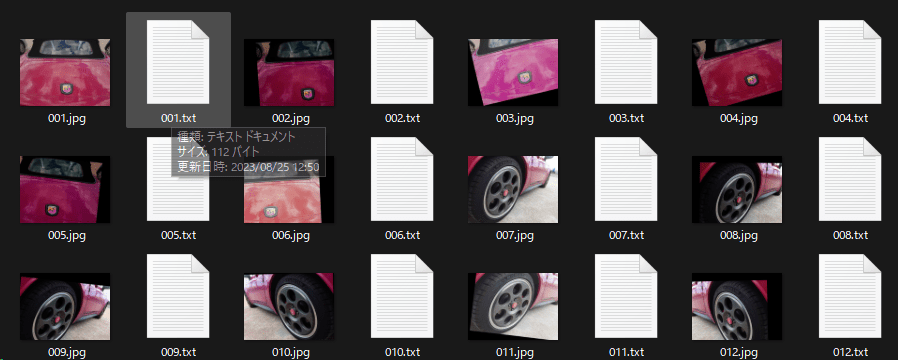
Step 6: タグ選定
Taggerによって出来たtxtファイルのタグの選定に入ります。
ここが非常にポイントになるのですが、生成された画像のタグから学習してもらいたいものを「削除」します。
学習に利用する画像は最低でも20枚程度必要となるので画像と同等のtxtファイルが生成されます。
それらすべてのtxtから学習させたいタグを削除していくのですが面倒ですのでプログラム的に処理してしまいます。
03_extract.batを起動してください。
このバッチファイルを実行すると対象となるフォルダを聞かれます。
imput_imgフォルダの配下にある対象となるLoRAのフォルダを入力して下さい。
ここでは10_abarth124のフォルダが対象なので10_abarth124と入力します。
Enterを押すと完了です。

all_words.txtを開きます。そこには先ほど指定した10_abarth124フォルダの配下にあるすべてのtxtファイルの単語が登録されています。
この中から学習して貰いたいtagを選定していきます。
ただこのタグも対象にあった場合に一つ一つ選定して行くのは面倒です。
なのでBing chatを利用してAIで選定してしまう方法があります。
Bingを起動したら次のように指示します。
---------------------------------------------------
次のデータから車に関するものを選択して下さい。124spider, car, vehicle focus, motor vehicle, ground vehicle, no humans, outdoors, road, grass, sports car, building, tree, scenery, day, photo background
---------------------------------------------------
するとそれっぽく選定してくれます。
先頭の124spiderはトリガーワードなのですべの*.txtに存在してますので消したくありません。Bingの結果に存在した場合はdelete_words.txtには含めないようにします。
ただBingはしれっと自信満々に間違った回答を出すので手作業で1つ1つ選定した方が良い気もします。
選定してくれたタグをLoRA_makeフォルダにあるdelete_words.txtに貼り付けます。
貼り付けが終わったら次に04_app_of_exclusions.batを起動します。
再び対象フォルダを聞かれますので10_124spiderと入力します。
Enterを押すと完了です。
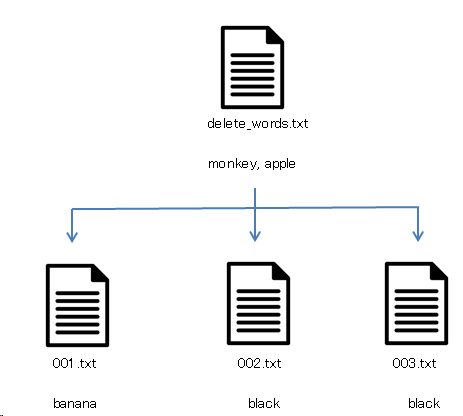
すると10_124spiderの配下にあるすべてのtxtファイルからdelete_words.txtに記載されたタグが消えます。
これでタグ付は完了です。
一番手間がかかる作業がこれで終わりです。あとはLoRAを作るだけです。
準備した素材を使って次の記事ではKohya_SSの使い方を解説します。
一度作業してみると次からはそんなに手間は掛からないにゃ。
一番大変なのは質の良い画像を集めることなのにゃ。
2回目からは全部読まなくても流れだけが解るように箇条書きで書いておくにゃ。
1.集めた画像をinput_padding_imagesに配置する。
2.01_augmentation.batを起動して画像を水増しする。
3.input_imgにリピート回数_LoRA名のフォルダを作る。
4.input_padding_imagesとoutput_padding_imagesの画像を前述で作成したフォルダに入れる。
5.02_file_rename.batを起動してファイル名を連番にする。
6.Taggerを利用してタグtxtを作成する。
7.03_extract.batを起動して作られたall_words.txtから削除するワードを選定する。
8.delete_words.txtに選定した削除ワードを張り付ける。
9.04_app_of_exclusions.batを起動してtxtファイルから削除ワードを除外する。
次はいよいよLoRAの作成なのにゃ。
[PR]